Joint Learning Approach for Machine Learning

Hello all, In this blog we will explore a novel model I developed which does fusion learning between 6 head CNN (multi-head) and Transformer for classification tasks like activities classification, or any other classification. I have written a paper on this which is accepted in the conference as well. For time-series dataset, you can replace CNNs with RNNs or can also use GRU.
Understanding the Approach
Convolutional Neural Networks (CNNs)
CNNs have been a cornerstone in image processing tasks due to their ability to capture spatial dependencies efficiently. In the context of activity monitoring, CNNs can effectively extract features from time-series sensor data, identifying patterns that characterize different activities.
Transformers
Transformers, initially proposed for natural language processing tasks, have shown remarkable capabilities in capturing long-range dependencies. When applied to sequential data, such as time-series, transformers excel at capturing contextual information across various time steps, thereby enhancing the model's understanding of temporal patterns.
Fusion Approach
The fusion of CNNs and Transformers aims to leverage the strengths of both architectures. While CNNs excel at feature extraction from local patterns, transformers complement this by capturing global dependencies, enabling the model to discern nuanced activity patterns spread across the entire sequence.
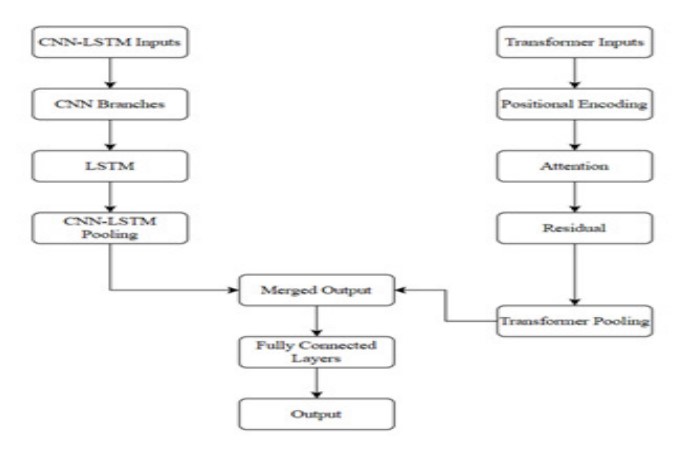
Architecture Overview
The joint learning architecture comprises two main components:
-
CNN LSTM: This branch consists of multiple CNN layers followed by LSTM layers. CNN layers extract spatial features, while LSTM layers capture temporal dependencies within the extracted features.
-
Transformer: The Transformer branch incorporates self-attention mechanisms to capture long-range dependencies. Additionally, positional encoding ensures that the model retains information about the sequential order of input data.
Diagram
Code
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Input, Conv1D, LSTM, Dense, Concatenate, GlobalAveragePooling1D, BatchNormalization, Dropout, MultiHeadAttention, LayerNormalization, Add
from tensorflow.keras.models import Model
from sklearn.model_selection import train_test_split
from tensorflow.keras.optimizers import Adam
# Custom Positional Encoding Layer
class PositionalEncoding1D(tf.keras.layers.Layer):
def __init__(self, input_dim, **kwargs):
super(PositionalEncoding1D, self).__init__(**kwargs)
self.pos_encoding = self.positional_encoding(input_dim, 256) # Adjust 256 as needed
def positional_encoding(self, position, d_model):
angle_rads = self.get_angles(np.arange(position)[:, np.newaxis], np.arange(d_model)[np.newaxis, :], d_model)
# Apply sine to even indices in the array; 2i
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
# Apply cosine to odd indices in the array; 2i+1
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...]
return tf.cast(pos_encoding, dtype=tf.float32)
def get_angles(self, position, i, d_model):
angle_rates = 1 / np.power(10000, (2 * (i // 2)) / np.float32(d_model))
return position * angle_rates
def call(self, inputs):
return inputs + self.pos_encoding
X_train = merged_train.drop(columns=['Activity'])
y_train = merged_train['Activity']
# Reshape X_train to match the input shape (561 features)
X_train = X_train.values.reshape(X_train.shape[0], 561, 1)
# Split the data into training and validation sets
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.3, random_state=0)
# Define input shape
input_shape = X_train.shape[1:]
# Input layer for CNN LSTM
cnn_lstm_inputs = Input(shape=input_shape)
# Feature Extraction Heads (6 CNN layers)
cnn_branches = []
for i in range(6):
cnn_branch = Conv1D(filters=128, kernel_size=3, activation='relu')(cnn_lstm_inputs)
cnn_branch = BatchNormalization()(cnn_branch)
cnn_branches.append(cnn_branch)
# Concatenate the CNN branches
cnn_output = Concatenate()(cnn_branches)
# LSTM layer
lstm_output = LSTM(units=256, return_sequences=True)(cnn_output)
lstm_output = LSTM(units=256, return_sequences=True)(lstm_output)
lstm_output = BatchNormalization()(lstm_output)
# Global Average Pooling for CNN LSTM
cnn_lstm_pooling_output = GlobalAveragePooling1D()(lstm_output)
# Input layer for Transformer
transformer_inputs = Input(shape=input_shape)
# Positional encoding layer for Transformer
positional_encoding = PositionalEncoding1D(input_shape[0])(transformer_inputs)
# Multi-Head Self-Attention layer for Transformer
attention_output = MultiHeadAttention(num_heads=8, key_dim=128)(positional_encoding, positional_encoding)
attention_output = LayerNormalization(epsilon=1e-6)(attention_output + positional_encoding)
# Residual connection
residual_output = Add()([attention_output, positional_encoding])
# Global Average Pooling for Transformer
transformer_pooling_output = GlobalAveragePooling1D()(residual_output)
# Concatenate outputs from both architectures
merged_output = Concatenate()([cnn_lstm_pooling_output, transformer_pooling_output])
# Fully connected layers
fc_output = Dense(512, activation='relu')(merged_output)
fc_output = Dropout(0.5)(fc_output)
fc_output = Dense(256, activation='relu')(fc_output)
fc_output = Dropout(0.5)(fc_output)
# Output layer (assuming you have 6 classes for activities)
num_classes = 6
output = Dense(num_classes, activation='softmax')(fc_output)
# Create the model
model = Model(inputs=[cnn_lstm_inputs, transformer_inputs], outputs=output)
# Compile the model
model.compile(optimizer=Adam(learning_rate=1e-4), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
batch_size = 64
num_epochs = 100
history = model.fit([X_train, X_train], y_train, epochs=num_epochs, batch_size=batch_size, validation_data=([X_val, X_val], y_val))
val_loss, val_accuracy = model.evaluate([X_val, X_val], y_val)
print(f"Validation Loss: {val_loss}, Validation Accuracy: {val_accuracy}")
Effectiveness of the Approach
Enhanced Feature Representation
By combining CNNs and Transformers, the model can effectively capture both local and global features. CNNs focus on spatial patterns, while Transformers capture temporal dependencies across the entire sequence. This leads to a richer feature representation, enabling the model to make more informed predictions.
Robustness to Sequence Length Variation
One challenge in activity monitoring datasets is the variance in sequence lengths. Traditional approaches struggle to handle varying sequence lengths effectively. However, the transformer architecture's self-attention mechanism allows the model to adapt to sequences of different lengths, making it more robust and versatile.
Improved Accuracy and Generalization
Experiments on activity monitoring datasets demonstrate that the joint learning approach consistently outperforms standalone CNN or Transformer models. The fusion of architectures leads to improved accuracy and generalization, enabling the model to classify activities with higher precision across diverse datasets.
Challenges and Future Directions
While the joint learning approach shows promise, several challenges warrant attention:
-
Computational Complexity: Training a joint CNN-Transformer model can be computationally intensive, especially for large datasets. Efficient strategies for model training and optimization are essential to mitigate computational overhead.
-
Hyperparameter Tuning: Balancing the hyperparameters of both CNN and Transformer components is crucial for optimal performance. Fine-tuning these hyperparameters requires careful experimentation and validation.
-
Interpretability: Despite achieving high accuracy, interpreting the decisions made by the joint model remains challenging. Enhancing model interpretability is crucial, especially in applications where transparency and trustworthiness are paramount.
-
Data Augmentation: Activity monitoring datasets often suffer from class imbalance and insufficient labeled data. Employing robust data augmentation techniques can help address these issues and improve model generalization.
Conclusion
The fusion of Convolutional Neural Networks and Transformers presents a compelling approach for activity monitoring tasks. By combining the strengths of both architectures, the joint learning model achieves superior performance in activity classification, robustness to sequence length variation, and improved generalization across diverse datasets. Despite encountering challenges such as computational complexity and interpretability, ongoing research efforts aim to address these limitations and further enhance the effectiveness of the joint learning approach. We at the end achieved an accuracy of 98% along with 98% F1-Score

Devrajsinh Jhala
Self-taught Developer with over 2 years of experience in developing websites. I want to help clients build websites with technologies like 𝗥𝗲𝗮𝗰𝘁.𝗷𝘀, 𝗡𝗲𝘅𝘁.𝗷𝘀, 𝗮𝗻𝗱 𝗧𝗮𝗶𝗹𝘄𝗶𝗻𝗱𝗖𝗦𝗦 to make their websites fast, and UX-friendly. I also love teaching the things I learn, so I also blog my learnings in a way for people with little knowledge to consume. Web-Developer: Made over 𝟱+ 𝗽𝗿𝗼𝗷𝗲𝗰𝘁𝘀 on web development with a range of technologies including Reactjs, Nextjs, TailwindCSS, Bootstrap, Redux, ContextAPI, etc. I believe in Learning by building and so I love applying what I learned to help clients build premium websites with the latest technologies to give their end-users the best experience possible. Additionally, I also love watching anime and playing online video games. Feel free to connect with me: Email: jhaladevrajsinh11@gmail.com